Organising Schematics with Python
I was given a folder of electrical and mechanical drawings in CAD file format to tidy up. These drawings all relate to Machine Instrumentation and Protection (MIPS) on the JET Tokamak.
My task was to update all the drawings, deleting old ones and adding modifications. I was to then organise them in a logical structure and create an excel database for the drawings. I did this all manually, the spreadsheet head is shown below.
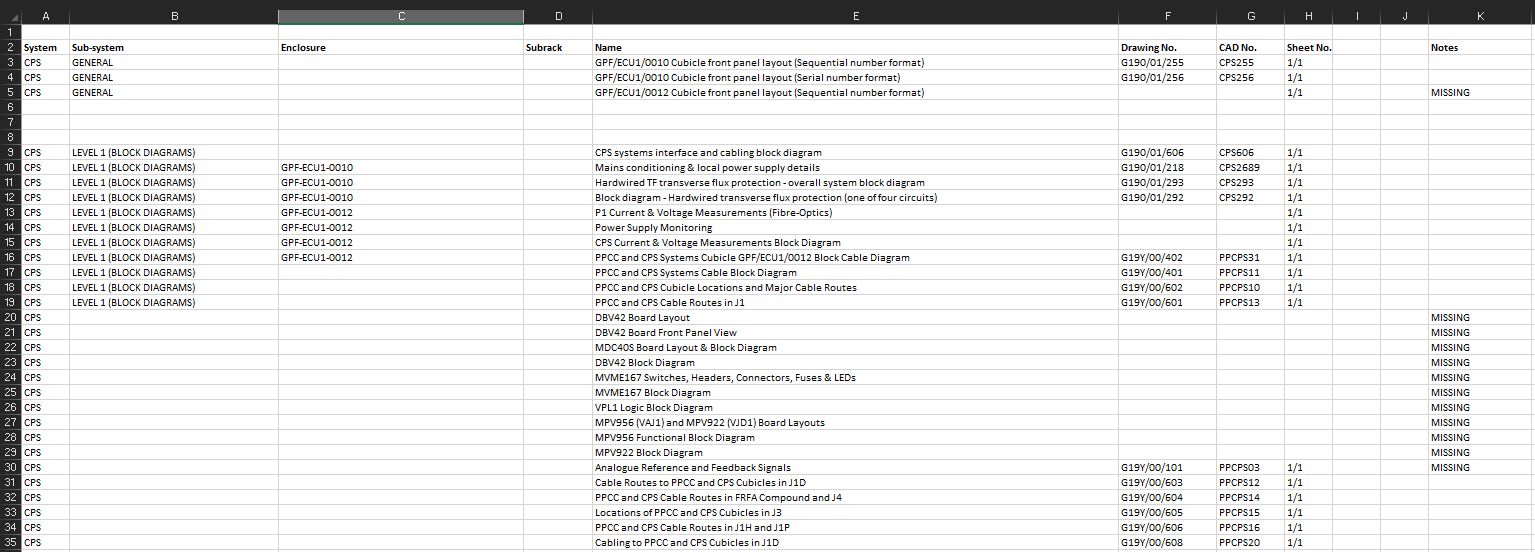
The structure of the drawings is hierarchical, but drawings can be found at any level.
-
 system
system
-
 drawing
drawing -
subsystem
-
drawing
-
enclosure
-
drawing
-
subrack
-
drawing
-
-
-
-
There are also many rows with missing information and many missing files.
To make this database more useful I decided to insert hyperlinks in each cell to link to the relevant folder or file. There are over 300 files here so after reading Automate the Boring Stuff with Python I decided to apply some python automation to the task.
I automated 2 tasks;
- Capitalise all file names in the database
- Add hyperlinks to all folders and files within an excel sheet
The full scripts are caps.py and linker.py, they are both in my Github python-scripts folder.
caps.py
This program is a simple example of using the os module to automate tedious tasks in the local file system. At its core the program is a cascading if statement where each if corresponds to a subfolder. The script keeps digging until it finds files, it then renames them with capital letters.
The following is the first if statement which applies to the highest level folder.
# If path is to a directory then loop through the folders inside
if os.path.isdir(path):
for folder in os.listdir(path):
# Store new file path for each folder
folderpath = os.path.join(str(path), str(folder))
# If path is to directory then loop through the folders inside
if os.path.isdir(folderpath):
for sub1folder in os.listdir(folderpath):
# Store new file path for each folder
sub1folderpath = os.path.join(str(folderpath), str(sub1folder))
### ……. Cascading through subfolders ……. ###
# If folderpath points to a file
elif os.path.isfile(folderpath):
# Rename that file as upper case
os.rename(folderpath, folderpath.upper())
print('\nProcess complete, please check files.\n')
# Error handling
elif os.path.isfile(path):
print('ERROR: The path you entered is to a file')
else:
print('ERROR: Invalid folder path')
linker.py
The linking program is slightly more complex. First we get the root folder of the database and the csv file name from the user and make sure these things exist. Then create an empty lists for each column like system = [].
I am using the XlsxWriter module to create a new spreadsheet in xlsx form which is identical to the original but with all cells linked to their folder or file.
Some set up is required to get this new spreadsheet ready.
# Define new workbook & worksheet
linkedworkbook = xlsxwriter.Workbook(filename + '-linked.xlsx') linkedworksheet = linkedworkbook.add_worksheet('sheet1')
# Set column A width to 9
linkedworksheet.set_column('A:A', 9)
# Format text to look like old workbook
text_format = linkedworkbook.add_format({
'bold': 1,
'underline': 1,
'font_size': 11, })
Next we loop through every row of the original spreadsheet with for i in range(wrkbook.shape[0]): and store strings for each of our categories in the relevant list: system.append(str(wrkbook.iloc[i, 0])).
We now have lists representing each column of the original spreadsheet that we can loop through using i like enclosure[i].
The next stage is to loop through the hierarchy from top to bottom for each row.
# Ensure system cell is not empty
if system[i] != 'nan':
# Define path to system folder
folderpath = os.path.join(rootfolder, system[i])
# Define path to (possible) CAD file
filepath = os.path.join(folderpath, CAD_name[i]) + '.DWG'
# Define cell name (system is in column A)
cell = 'A' + str(i)
# xlsxwriter function writes ‘folderpath’ as a hyperlink into ‘cell’ and displays system[i] in the cell and on hover
linkedworksheet.write_url(cell, folderpath, string=system[i], tip=system[i])
This statement within the for loop will link every row where system != ‘nan’ to the folder with the address ‘rootfolder/system[i]’. For example if rootfolder = ‘C://users/CADfolder’ and system[5] = ‘CPS’ then row 5 of the system row will be linked to ‘C://users/CADfolder/CPS’.
Now we must deal with any CAD files that may be in this top level folder, it’s more likely they will be at the bottom of the hierarchy but there are some at all levels so we must account for all. Below the linkedworksheet.write_url line, within the same if statement, we have
# Do this action only if a CAD file with the name stored in filepath exists
if os.path.isfile(filepath):
# Redefine cell (CAD file name is in column G)
cell = 'G' + str(i)
# Create hyperlink, the same as for a folder
linkedworksheet.write_url(cell, filepath, string=CAD_name[i], tip=CAD_name[i])
These two if statements are recreated for subsystem, enclosure, and subrack.
The last thing to add is the other information on the sheet which is does not need to have a hyperlink. XlsxWriter can be used again to write strings instead of links.
if name[i] != 'nan':
cell = 'E' + str(i)
linkedworksheet.write_string(cell, name[i])
This is done for the name, drawing no., and sheet no. columns.
Finally linkedworkbook.close() to close and save the new excel spreadsheet. The output is shown below.
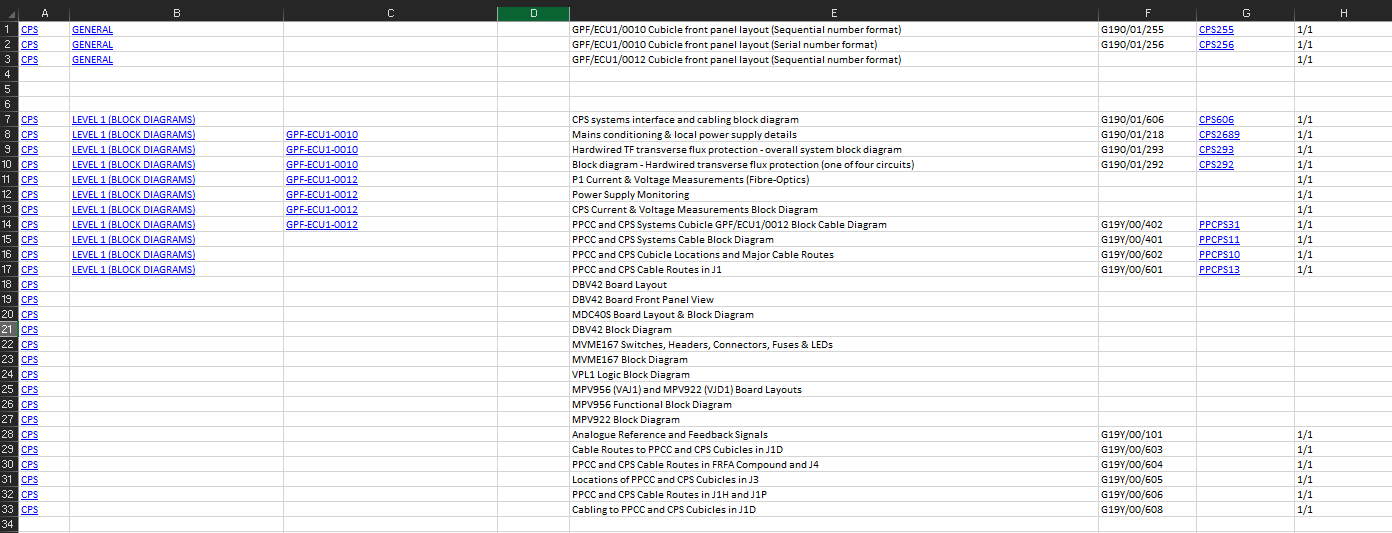
Clicking any link associated with a folder will open that folder in the file explorer. Clicking a CAD drawing name will open that drawing in AutoCAD. The hope is that this database can be used to quickly find drawings and schematics.
Some features I’d like to add are included as comments in the code files on Github. These include re-adding the column headings in the final spreadsheet and generally making the script more adaptable to different use cases.